There are many languages in the world, but most of them are minority languages, and many of them are in danger of extinction. Many attempts have been made to preserve such languages as audio data. Still, it isn't easy to utilize the recorded data because it takes a lot of time and effort to transcribe the audio. In this research project, we are developing a technology to use the speech data of such minority languages.
One way to utilize the data is spoken term detection (STD), a method of searching for occurrences of keywords in a speech database using speech as the search key. Conventionally, we extract acoustic features such as MFCCs from both the query speech and the database. Then we match the features using a matching method that allows for expansion and contraction (e.g., continuous DP matching) to measure the distance between the sequences of acoustic features, and keywords are detected where the distance is small. The problem with this method is that the distance between acoustic features is affected not only by pronunciation content but also by speaker differences. Ideally, we should use features that are sensitive to linguistic pronunciation differences but not to speaker differences. The posteriorgram is the posterior probabilities of phonemes calculated by phoneme recognition from a short period of speech. By performing speaker-independent phoneme recognition, the posteriorgram can absorb speaker differences and represent only pronunciation differences. The posteriorgram is language-dependent, and phoneme recognizers cannot be trained for minority languages. Therefore, conventional posteriorgram cannot be directly used for STD of minority languages.
In this study, we developed a method to improve the accuracy of STD for minority languages by combining multiple posteriorgrams of many-resource languages (such as English, Japanese, and Chinese). In this study, we compared the STD performance under various conditions, with Kaqchikel as the target language and English and Japanese as the many-resource languages. As a result, we improved the detection performance of Kaqchikel by combining the posteriorgrams trained from English and Japanese to create new features.
THEME
Utilization of speech database for minority languages
- 代表者
- Akinori Ito(Graduate School of Engineering)
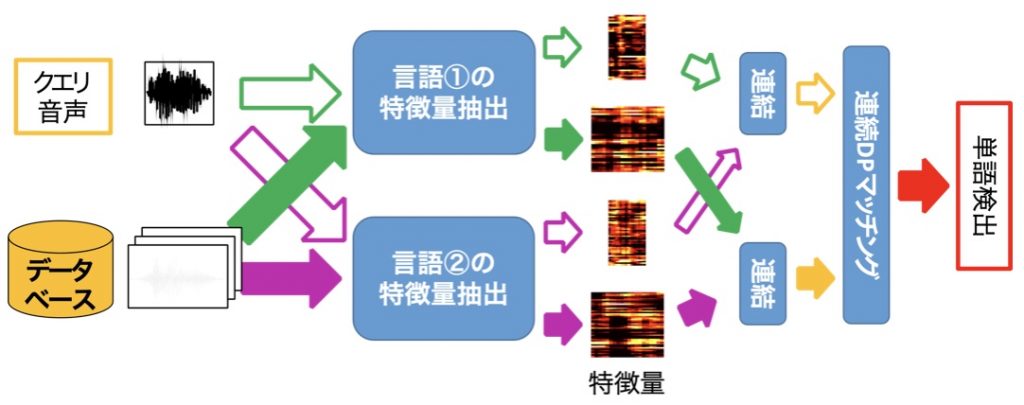
- Fig. 1. Spoken Term Detection using posteriorgrams of multiple languages.
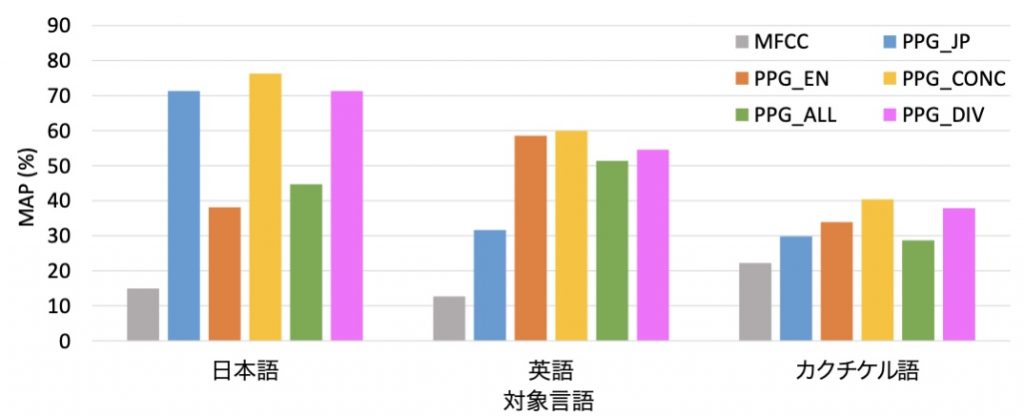
- Fig. 2. STD results for Japanese, English and Kaqchikel speech database. PPG_EN and PPG_JP are posteriorgrams of English and Japanese, respectively. PPG_CONC is the concatenated posteriorgram of English and Japanese. PPG_ALL and PPG_DIV are posteriorgrams trained using both English and Japanese. PPG_CONC showed the best detection performance (Mean Average Precision, MAP) among all the features.