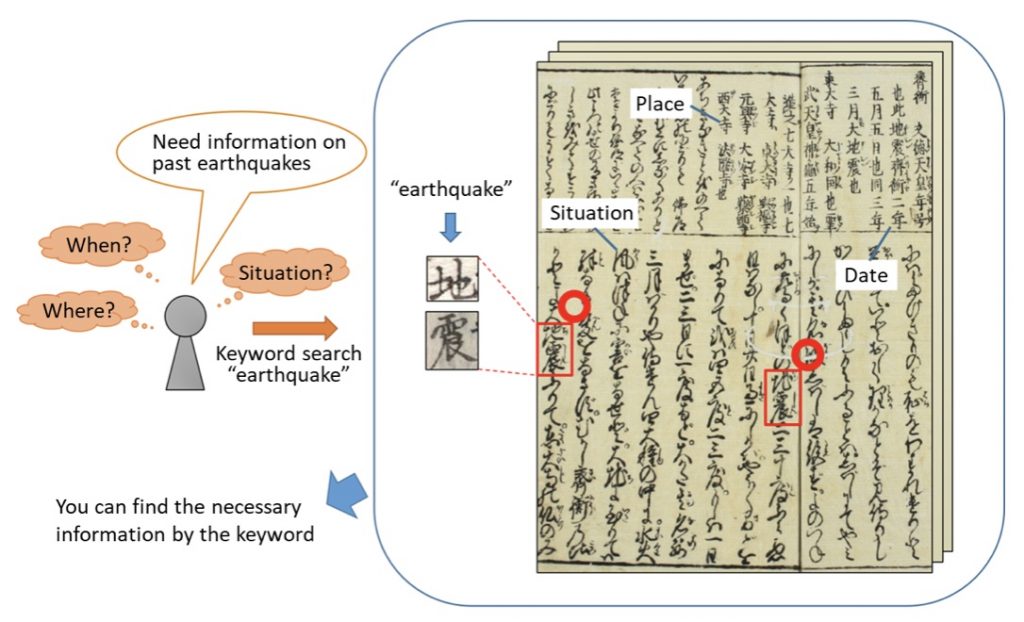
The purpose of this research project is to enhance the creativity of the humanities by developing a highly accurate retrieval technology for large-scale data of historical documents and reconsidering the research methods of the humanities.
Since it is not easy to recognize various kinds of characters in the historical documents precisely, we are developing a method for realizing retrieval using the similarity of images instead of recognizing each character. Given a text as the search word, an image that represents the text is generated. By calculating the similarity of the text image and each region of the historical document images, the area where the target search word exists is determined. On the other hand, we are developing a method of recognizing characters in the historical documents by making full use of machine learning technology. In machine learning, the amount of labeled data that can be used as training data greatly affects the recognition accuracy. It is not possible to prepare a sufficient number of training data for all character types for each historical document because the shape differs depending on the characters. In order to solve this, we are trying to recognize the entire character by recognizing the component (radical) of the character.
In the process of creating novel humanities research field, it is expected that there will be considerable change and pluralization to the ordinary values of information. In the situation where the value of information changes and its diversification progresses, we can practice information prioritization research on what kind of prioritization is appropriate, which is also a characteristic of this research.
THEME
Utilization of historical documents
- 代表者
- Shinichiro Omachi(Graduate School of Engineering)